
Multisite is a function specially developed for Patroni that makes it possible to combine two separate Patroni clusters into a common cluster unit. ‘Separate’ in this context means that the clusters run independently of each other and can even be located on different Kubernetes clusters. With Multisite, both clusters benefit from the well-known Patroni features such as automatic failover and demotion of members, resulting in a significant extension compared to a conventional standby cluster. This feature significantly improves high availability and redundancy by managing multiple geographically or infrastructurally separated clusters as one logical unit. This allows one cluster to seamlessly transition to another in the event of a failure without having to rely on manual switchovers or third-party replication solutions.
In order to set up the multisite PostgreSQL operator you will need the following:
- Two or more Kubernetes or OpenShift clusters (also possible with bare metal or VMs)
- Kubernetes version 1.25+, OpenShift version 4.12+.
- Support for defining LoadBalancer services with external IP addresses that are accessible from the other cluster(s).
- Persistent volumes with must be available (only ReadWriteOnce capability is needed).
- A separate VM or Kubernetes/OpenShift cluster to provide quorum (if using less then three Kubernetes or OpenShift clusters).
- For high availability there should not be a shared point of failure between the quorum and the two Kubernetes clusters.
- VM or a LoadBalancer IP must be accessible on ports 2379/2380 to the two other clusters.
- 2 vCPU and 2 GB of memory and 20GB of persistent storage is needed for the quorum site.
- Set up etcd cluster with 3 sites accessible from each of the sites. etcd needs to support API version 3.
- For backups an object storage system with S3 compatible API is needed. Minio, Ceph and major cloud provider object storages are known to work.
ImportantAn additional etcd is set up for Multisite, which spans the Kubernetes or Openshift clusters and must contain the quorum.
Helm based deployment of the multisite operator contains two helm charts, postgres-operator and postgres-cluster. The first is used to deploy the operator and associated objects to a single Kubernetes cluster. The operator is responsible for managing PostgreSQL clusters based on Custom Resource Definitions (CRDs) of type postgresqls/pg.
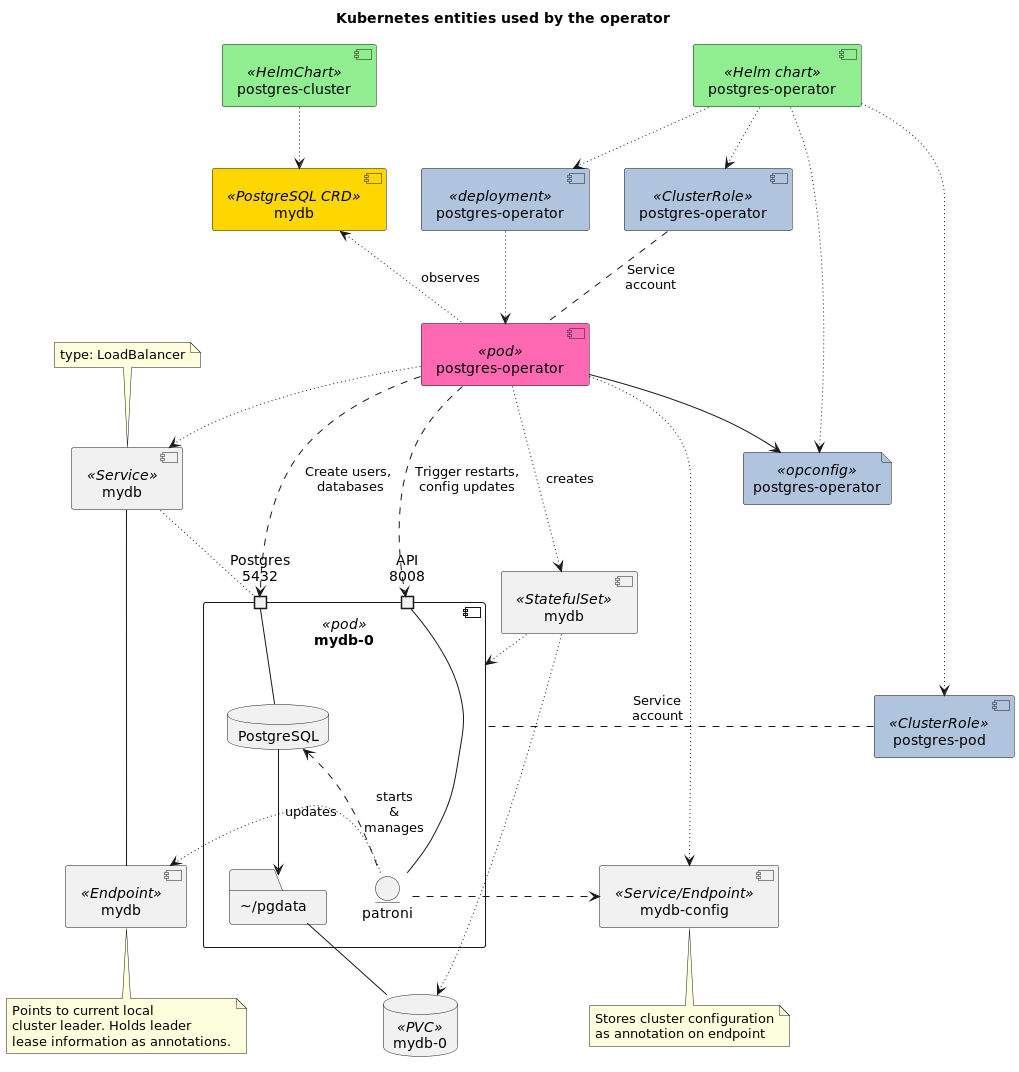
The diagram contains in green the Helm charts that are used to deploy operator and clusters, in blue the objects deployed by the operator helm chart and in gold the objects deployed by the cluster chart.
Operator helm chart deployed objects have the following purposes:
deployments/postgres-operator- Deployment for the operator itself.opconfig/postgres-operator- Operator configuration parameters that are read on operator startup. These apply to all clusters managed by this operator.crd/operatorconfigurations.cpo.opensource.cybertec.at- Schema for the operator configuration.clusterrole/postgres-operator- Defines the Kubernetes API resource access used by the operator. Assigned to postgres-operator service account.clusterrole/postgres-pod- The Kubernetes API access needed by database pods. Access is needed to access leader status, config and other things. This is assigned to postgres-pod service account used by database pods.crd/postgresqls.cpo.opensource.cybertec.at- Schema for PostgreSQL cluster definitions.clusterrole/postgres-operator:users:{admin,edit,view}- Ifrbac.createAggregateClusterRolesis set then user facing roles are added for accessing the postgresqls CRDs.
The cluster chart creates an instance of postgresqls CRD, which will be called cluster manifest from here on. When this cluster manifest is created operator will create the needed resources for the cluster. These include:
statefulset/$clustername- StatefulSet is responsible for creating and managing database pods and their associated PersistentVolumeClaims for storing the databases. Each database pod will run internally an instance of Patroni process, which will coordinate over the Kubernetes API initialization of the database, startup, leader election and other control plane actions.service/$clustername,endpoints/$clustername- The main access point for users accessing the database. When load balancer is enabled in the CRD or multisite mode is enabled, this service will be set to be a LoadBalancer service and accessible from outside the Kubernetes cluster. The service is created without a selector. Instead, for leader elections database pods will update the IP address of this endpoint to point to the current leader.The endpoint also holds annotations that determine the duration of the leader lease.
In multicluster operation mode the standby site leader will be in read-only mode.
service/$clustername-repl- Service that points to non-leader (read-only) instances of the database cluster.service/$clustername-config- A headless service with an endpoint that holds Patroni configuration in annotations.poddisruptionbudget/postgres-$clustername-pdb- A pod disruption budget that does not allow Kubernetes to shut down pods in leader role. On some Kubernetes clusterskubernetes.enable_pod_disruption_budgetsmay need to be turned off to allow nodes to be drained for upgrades.
In multisite operation mode there are multiple independent Kubernetes clusters with operators capable of independent operation. To coordinate which site has the current leader process the database pods use a shared etcd cluster to store a leader lease.
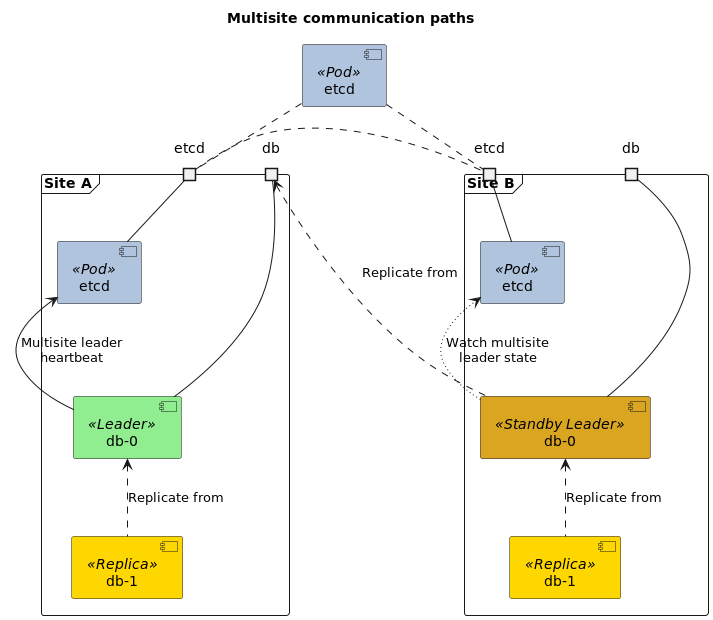
During bootstrap the first site to acquire the leader lease gets to initialize the database contents. Secondary sites are configured to replicate from primary site using Patroni’s standby_cluster mechanism.
To be able to communicate between Kubernetes clusters a LoadBalancer service is needed. For this the operator automatically turns the primary service of the cluster to be of kind LoadBalancer. Operator will wait for an external IP address to be assigned to this service and passes this information to the database pod. The leader of each site, whether primary or standby site, will periodically advertise the externally visible IP address for their site in etcd. Based on this the standby site can configure the standby cluster mechanism to replicate from primary site.
In multisite mode postgres-operator can manage a replicated PostgreSQL cluster that is deployed across multiple Kubernetes clusters. Multisite operation can be turned on on a cluster by cluster basis, or can be configured to default to on for all cluster managed by a single operator.
Setting up a GR deployment consists of the following steps:
- Creating a shared etcd cluster.
- Configuring multisite operation parameters for the postgres-operator.
- Creating a multisite enabled cluster.
Multisite operation mode requires an etcd cluster to achieve consensus on which site gets to accept write transactions. This functionality is critical to avoid situations where multiple site accept incompatible writes that cannot be reconciliated, also known as a split brain scenario.
A highly available etcd cluster consists of an odd number of nodes, at least 3. It is very important that a quorum of etcd instances (for 3 node clusters, any two instances) do not share a single point of failure. Otherwise the write availability of database clusters is limited to this single point of failure. Effectively this means that to protect 3 node etcd clusters from whole site failure, any site can only contain 1 etcd node and there needs to be at least 3 sites.
Postgres-operator is agnostic to the exact method of etcd setup, but for ease of use there is a Helm chart packaged that demonstrates the setup.
This example uses one etcd instance deployed outside Kubernetes cluster as quorum. This etcd needs to be started with the following configuration. Note that IP address that is advertised must be routed to the host that runs this etcd.
ETCD_NAME=quorum
ETCD_INITIAL_CLUSTER=quorum=http://10.100.1.100:2380
ETCD_INITIAL_ADVERTISE_PEER_URLS=http://10.100.1.100:2380
ETCD_INITIAL_CLUSTER_TOKEN=hpe_etcd
ETCD_ADVERTISE_CLIENT_URLS=http://10.100.1.100:2379
ETCD_LISTEN_CLIENT_URLS=http://0.0.0.0:2379
ETCD_LISTEN_PEER_URLS=http://0.0.0.0:2380
Kubernetes clusters can then be joined to this node. This needs to be a two step process as typically the externally visible IP address or port is not known before creating the LoadBalancer service. For this first create a free standing loadbalancer service that will be overwritten by the Helm chart.
helm template global-etcd ./etcd-helm/ -f etcd-helm/site_a.yaml \
| awk '/service.yaml/{flag=1;next}/---/{flag=0}flag' \
| kubectl apply -f -
Then check what external IP address the load balancer service got assigned to it.
$ kubectl get svc -l app.kubernetes.io/instance=global-etcd
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
global-etcd-etcd-helm LoadBalancer 10.109.171.146 10.200.1.101 2379:32488/TCP,2380:30336/TCP 17h
And set in the values for the helm chart:
- Unique name of the site.
- Externally visible IP address of this service
- IP address of existing etcd service.
- Peer list that includes both existing and to be added etcd instance.
Example:
site:
name: site_a
host: 10.100.2.101
etcd:
existing_etcd_cluster_hostname: 10.100.1.100
token: hpe_etcd
state: existing
peers:
#Peers should only include working peers and the current one
- quorum=http://10.100.1.100:2380
- site_a_etcd0=http://10.100.2.101:2380
client_port: 2379
peer_port: 2380
Then install the helm chart:
helm install global-etcd ./etcd-helm/ -f etcd-helm/site_a.yaml
This then needs to be repeated for the other site.
Multisite operation needs at a minimum the configuration options multisite.etcd_host, multisite.site
and multisite.enabled. All of them can be configured either in operator configuration or per cluster.
multisite.etcd_host needs to point at the global etcd. The port is currently assumed to be 2379. Normally
all clusters under one operator would be using the same etcd clusters, so it makes sense to configure it
in the operator configuration. At runtime database pods will discover the whole etcd cluster member list
and will also take notice of any membership changes. It is enough to use local etcd instance service name
here.
multisite.site is a unique identifier for this site. It will be prefixed to globally advertised database pod names
to distinguish them from pods in other sites. This also makes sense in the operator configuration.
multisite.enabled turns of the multisite behavior. Typically it would make sense to control this at the
cluster level, but the default could be turned on globally.
These parameters are exposed in Helm chart values file as configMultisite.*.
Example config:
$ kubectl get opconfig/postgres-operator -o yaml | grep multisite -B1 -A3
min_instances: -1
multisite:
etcd_host: global-etcd-etcd-helm.default.svc.cluster.local
site: s1
postgres_pod_resources:
This needs to be repeated with a different site name in the second Kubernetes cluster.
If the operator is configured for multisite operation then creating a multisite cluster only needs enabling of the multisite mode.
Here is an example values file to use for creating multisite enabled clusters:
apiVersion: cpo.opensource.cybertec.at/v1
kind: postgresql
metadata:
name: multisite-cluster
namespace: cpo
labels:
app.kubernetes.io/name: postgres-cluster
app.kubernetes.io/instance: multisite-cluster
spec:
dockerImage: docker.io/cybertecpostgresql/cybertec-pg-container:postgres-multisite-17.4-1
numberOfInstances: 1
postgresql:
version: '17'
resources:
limits:
cpu: 500m
memory: 500Mi
requests:
cpu: 500m
memory: 500Mi
teamId: acid
volume:
size: 5Gi
patroni:
ttl: 30
loop_wait: 10
retry_timeout: 10
multisite:
enable: true
There is no coordination needed between creating the two or more sites and they can use identical configuration. The clusters need to be in the same namespace and have the same name to be considered the same cluster. The first cluster to boot up will acquire multisite leader status and will bootstrap the database. The other clusters will automatically fetch a copy from the leader cluster and start replicating.
Multisite operation needs that the database cluster are capable of communicating with each other. To do this a load balancer service is created in each cluster for the cluster leader. The operator then waits for an external IP to be assigned and injects it into the database pods to be used for advertising their identity.
If database pods have not been created, the first place to check for information is operator logs. Operator logs can be checked with the following command (add –follow if you want to observe in real-time):
kubectl logs $(kubectl get po -l 'app.kubernetes.io/name=postgres-operator' -o name)
The logs for a successful cluster creation look like this
time="2023-02-22T15:24:12Z" level=info msg="ADD event has been queued" cluster-name=cpo/multisite-cluster pkg=controller worker=1
time="2023-02-22T15:24:12Z" level=info msg="creating a new Postgres cluster" cluster-name=cpo/multisite-cluster pkg=controller worker=1
time="2023-02-22T15:24:12Z" level=warning msg="master is not running, generated master endpoint does not contain any addresses" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:12Z" level=info msg="endpoint \"cpo/multisite-cluster\" has been successfully created" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:12Z" level=debug msg="final load balancer source ranges as seen in a service spec (not necessarily applied): [\"0.0.0.0/0\"]" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:12Z" level=info msg="master service \"cpo/multisite-cluster\" has been successfully created" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:12Z" level=info msg="replica service \"cpo/multisite-cluster-repl\" has been successfully created" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:12Z" level=debug msg="team API is disabled" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:12Z" level=debug msg="team API is disabled" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:12Z" level=info msg="users have been initialized" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:12Z" level=info msg="syncing secrets" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:12Z" level=debug msg="created new secret cpo/postgres.multisite-cluster.credentials.postgresql.cpo.opensource.cybertec.at, namespace: default, uid: 75ded2eb-a2c9-4968-a1d7-50d2996baeb3" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:13Z" level=debug msg="created new secret cpo/standby.multisite-cluster.credentials.postgresql.cpo.opensource.cybertec.at, namespace: default, uid: 45a2560a-65a8-4bd5-954f-34d80d8a1894" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:13Z" level=info msg="secrets have been successfully created" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:13Z" level=info msg="pod disruption budget \"cpo/postgres-multisite-cluster-pdb\" has been successfully created" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:13Z" level=info msg="waiting for load balancer IP to be assigned" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:13Z" level=debug msg="created new statefulset \"cpo/multisite-cluster\", uid: \"b83647ea-17f6-40aa-aa0c-b1111e76cdc0\"" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:13Z" level=info msg="statefulset \"cpo/multisite-cluster\" has been successfully created" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:13Z" level=info msg="waiting for the cluster being ready" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:16Z" level=debug msg="Waiting for 1 pods to become ready" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="pods are ready" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="Create roles" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=debug msg="closing database connection" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="users have been successfully created" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=debug msg="closing database connection" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="databases have been successfully created" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="found pod disruption budget: \"cpo/postgres-multisite-cluster-pdb\" (uid: \"986a0118-83e7-4736-9843-ec80c0ea9270\")" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="found statefulset: \"cpo/multisite-cluster\" (uid: \"b83647ea-17f6-40aa-aa0c-b1111e76cdc0\")" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="found secret: \"cpo/postgres.multisite-cluster.credentials.postgresql.cpo.opensource.cybertec.at\" (uid: \"75ded2eb-a2c9-4968-a1d7-50d2996baeb3\") namesapce: default" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="found secret: \"cpo/standby.multisite-cluster.credentials.postgresql.cpo.opensource.cybertec.at\" (uid: \"45a2560a-65a8-4bd5-954f-34d80d8a1894\") namesapce: default" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="found master endpoint: \"cpo/multisite-cluster\" (uid: \"d9f7870e-dd51-4a88-a36a-1c2eb258a31c\")" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="found master service: \"cpo/multisite-cluster\" (uid: \"4b30df50-ca53-4def-8171-b792c4eefc17\")" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="found replica service: \"cpo/multisite-cluster-repl\" (uid: \"a77c3a49-3eea-4b6b-92b1-032e13d78f02\")" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="found pod: \"cpo/multisite-cluster-0\" (uid: \"9b31d378-c9eb-4c1a-8637-e78933187ed7\")" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="found PVC: \"cpo/pgdata-multisite-cluster-0\" (uid: \"03e66572-27ed-42b4-87bd-825d32131d36\")" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=debug msg="syncing connection pooler (master, replica) from (false, nil) to (false, false)" cluster-name=cpo/multisite-cluster pkg=cluster worker=1
time="2023-02-22T15:24:28Z" level=info msg="cluster has been created" cluster-name=cpo/multisite-cluster pkg=controller worker=1
When database pods have been created, then Patroni logs can be checked from the pod logs:
kubectl logs multisite-cluster-0
Successful start of first database pod will have amongst other output the following lines:
. . .
# Kubernetes API access
2023-02-22 15:24:21,061 INFO: Selected new K8s API server endpoint https://192.168.49.2:8443
. . .
# Set ourselves as multisite leader
2023-02-22 15:24:21,218 INFO: Selected new etcd server http://192.168.50.101:2379
2023-02-22 15:24:21,348 INFO: Running multisite consensus.
2023-02-22 15:24:21,349 INFO: Touching member s1-multisite-cluster with {'host': '192.168.49.103', 'port': 5432}
2023-02-22 15:24:21,447 INFO: Became multisite leader
. . .
# Initializing a new empty database
2023-02-22 15:24:21,563 INFO: trying to bootstrap a new cluster
. . .
Success. You can now start the database server using:
. . .
# Database started
2023-02-22 15:24:23,934 INFO: postmaster pid=73
. . .
# Running global database intitialization script
2023-02-22 15:24:25,061 INFO: running post_bootstrap
. . .
# Bootstrap done
2023-02-22 15:24:26,310 INFO: initialized a new cluster
. . .
# Repeated information about health every 10s
2023-02-22 15:24:26,313 INFO: Lock owner: multisite-cluster-0; I am multisite-cluster-0
2023-02-22 15:24:26,361 INFO: Triggering multisite hearbeat
2023-02-22 15:24:26,364 INFO: Running multisite consensus.
2023-02-22 15:24:26,364 INFO: Multisite has leader and it is us
2023-02-22 15:24:26,409 INFO: Updated multisite leader lease
2023-02-22 15:24:26,409 INFO: Touching member s1-multisite-cluster with {'host': '192.168.49.103', 'port': 5432}
2023-02-22 15:24:26,422 INFO: no action. I am (multisite-cluster-0), the leader with the lock
. . .
Bootstrap of standby on primary site will have these lines:
. . .
# Determine leader
2023-02-22 15:47:04,552 INFO: Lock owner: multisite-cluster-0; I am multisite-cluster-1
2023-02-22 15:47:04,677 INFO: trying to bootstrap from leader 'multisite-cluster-0'
. . .
# Data copied to replica successfully
2023-02-22 15:47:06,805 INFO: replica has been created using basebackup_fast_xlog
2023-02-22 15:47:06,807 INFO: bootstrapped from leader 'multisite-cluster-0'
# Postgres up
2023-02-22 15:47:07,205 INFO: postmaster pid=73
. . .
# Normal operation
2023-02-22 15:47:08,380 INFO: no action. I am (multisite-cluster-1), a secondary, and following a leader (multisite-cluster-0)
Standby cluster will have the following information:
. . .
# Discovering multisite status
2023-02-22 15:49:58,406 INFO: Running multisite consensus.
2023-02-22 15:49:58,407 INFO: Touching member s2-multisite-cluster with {'host': '192.168.50.103', 'port': 5432}
2023-02-22 15:49:58,454 INFO: Multisite has leader and it is s1-multisite-cluster
2023-02-22 15:49:58,454 INFO: Multisite replicate from Member(index='118', name='s1-multisite-cluster', session='4113060022582527194', data={'host': '192.168.49.103', 'port': 5432})
2023-02-22 15:49:58,454 INFO: Setting standby configuration to: {'host': '192.168.49.103', 'port': 5432}
2023-02-22 15:49:58,455 INFO: Touching member s2-multisite-cluster with {'host': '192.168.50.103', 'port': 5432}
. . .
# Acquiring standby site leader status and starting copy from primary site
2023-02-22 15:49:58,290 INFO: Lock owner: None; I am multisite-cluster-0
2023-02-22 15:49:58,566 INFO: trying to bootstrap a new standby leader
. . .
# Replica creation successful
2023-02-22 15:50:00,326 INFO: replica has been created using basebackup
2023-02-22 15:50:00,327 INFO: bootstrapped clone from remote master postgresql://192.168.49.103:5432
# Postgres started
2023-02-22 15:50:00,577 INFO: postmaster pid=58
. . .
# Normal operation output of standby leader
2023-02-22 15:50:01,835 INFO: Lock owner: multisite-cluster-0; I am multisite-cluster-0
2023-02-22 15:50:01,886 INFO: Triggering multisite hearbeat
2023-02-22 15:50:01,888 INFO: Running multisite consensus.
2023-02-22 15:50:01,888 INFO: Multisite has leader and it is s1-multisite-cluster
2023-02-22 15:50:01,888 INFO: Multisite replicate from Member(index='118', name='s1-multisite-cluster', session='4113060022582527194', data={'host': '192.168.49.103', 'port': 5432})
2023-02-22 15:50:01,888 INFO: Touching member s2-multisite-cluster with {'host': '192.168.50.103', 'port': 5432}
2023-02-22 15:50:01,899 INFO: no action. I am (multisite-cluster-0), the standby leader with the lock
In case access to PostgreSQL logs is needed, the easiest way is to exec into a running database pod
with kubectl exec -it multisite-cluster-0 -- bash and view the files there. Logs are stored
as /home/postgres/pgdata/pgroot/pg_log/postgresql-*.csv, with one file per weekday.
Replication state can be queried from PostgreSQL:
kubectl exec -it $(kubectl get -o name po -l 'spilo-role=master,cluster-name=multisite-cluster') -- su postgres -c \
'psql -xc "SELECT application_name, client_addr, backend_start, write_lag FROM pg_stat_replication"'
To check how multisite mode is doing one option is to check the etcd state. For example by executing in any one of your database pods:
kubectl exec multisite-cluster-0 -- bash -c \
'ETCDCTL_API=3 etcdctl --endpoints=http://${MULTISITE_ETCD_HOST}:2379 \
get /multisite/${POD_NAMESPACE}/${SCOPE}/{leader,members0}'
This will output state stored in etcd. Example:
/multisite/cpo/multisite-cluster/leader
s1-multisite-cluster
/multisite/cpo/multisite-cluster/members/s1-multisite-cluster
{"host":"192.168.49.102","port":5432}
/multisite/cpo/multisite-cluster/members/s2-multisite-cluster
{"host":"192.168.50.102","port":5432}
Each cluster state is stored with the prefix /multisite/$NAMESPACE/$CLUSTER_NAME. In this state
there is /leader key storing current leader of the cluster and /members/$SITE_$CLUSTER_NAME for
each sites externally visible service.
Sometimes it is necessary to move leader role from one site to another. For this the operator REST API has an endpoint
named /clusters/$namespace/$cluster/multisite/. This accepts a POST request with a request JSON. The document has the
following attributes:
- switchover_to: name of the site that should become the new multisite leader.
Example:
curl --data-raw '{"switchover_to": "s1"}' -H "Content-type: application/json" \
http://postgres-operator.default.svc.cluster.local:8080/clusters/cpo/multisite-cluster/multisite/
The POST request to this endpoint will return immediately when the switchover request has been registered. The actual switchover process will take some time to coordinate.
Current multisite status is published to cluster CRD status subresource in Multisite field. The possible values
are Leader and Standby. When the role changes there will also be an event published.
Example output from a kubectl describe on the cluster CRD resource:
Status:
Multisite: Leader
Postgres Cluster Status: Running
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Promote 13s patroni Acquired multisite leader status
Ouptut from the standby side:
Status:
Multisite: Standby
Postgres Cluster Status: Running
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Demote 62s patroni Lost leader lock to s1-multisite-cluster
Normal Multisite 97s postgres-operator Multisite switching over to "multisite-cluster" at site "s1"
Normal Multisite 97s postgres-operator Successfully started switchover to "multisite-cluster" at "s1"
Minikube is a useful distribution for deploying development Kubernetes clusters. With a bit of configuration it is possible to set up 2 Minikube clusters with MetalLB deployed so that MetalLB assigned IP addresses are accessible from the other cluster.
Pre-requisite is to have 2 virtual machines that either are in the same L2 network, or that have a subnet routed to them.
This example is based on docker based deployment, same approach might work with other deployment options (e.g. Virtualbox), but may require some extra configuration tuning.
Start minikube’s on the two hosts using different internal subnets, and configure and enable the metallb addon to assign IP addresses from this subnet. The subnets chosen should not be in use for services needed by these two VMs, but other hosts are not affected by the choice of the subnets.
# Host A
minikube start --subnet=192.168.49.2
minikube addons configure metallb
-- Enter Load Balancer Start IP: 192.168.49.100
-- Enter Load Balancer End IP: 192.168.49.200
▪ Using image docker.io/metallb/speaker:v0.9.6
▪ Using image docker.io/metallb/controller:v0.9.6
✅ metallb was successfully configured
minikube addons enable metallb
# Host B
minikube start --subnet=192.168.50.2
minikube addons configure metallb
-- Enter Load Balancer Start IP: 192.168.50.100
-- Enter Load Balancer End IP: 192.168.50.200
▪ Using image docker.io/metallb/speaker:v0.9.6
▪ Using image docker.io/metallb/controller:v0.9.6
✅ metallb was successfully configured
minikube addons enable metallb
On both hosts turn on ip forwarding in sysctl.conf and reload it with sysctl -p
net.ipv4.ip_forward=1
In IP tables allow forwarding:
sudo iptables -A FORWARD -j ACCEPT
Configure on each host routing to access the other clusters metallb IP range via the other VMs IP address (need to replace IP addresses and network interfaces with actual ones from the VMs):
# Host A
sudo ip route add 192.168.50.0/24 via 192.168.2.12 dev eth1
# Host B
sudo ip route add 192.168.49.0/24 via 192.168.2.11 dev eth1
To check if load balancer works, here’s an example HTTP service:
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-blue-whale
spec:
replicas: 1
selector:
matchLabels:
app: hello-blue-whale-app
template:
metadata:
name: hello-blue-whale-pod
labels:
app: hello-blue-whale-app
spec:
containers:
- name: hello-blue-whale-container
image: vamsijakkula/hello-blue-whale:v1
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: hello-blue-whale-svc
labels:
app: hello-blue-whale-app
spec:
selector:
app: hello-blue-whale-app
type: LoadBalancer
ports:
- port: 80
targetPort: 80
Then check what external ip got assigned to the service (should be the first IP from the range given above).
kubectl get svc/hello-blue-whale-svc
And then from the other host use curl to see if the service can be accessed.
curl -v http://192.168.49.100/
Other hosts on the same network can have the same routes added to access services in the clusters. If access from other networks is needed, then the chosen subnets need to be routed to these VMs across your network.